Introduction : je suis un dev dans un bunker numérique
Je suis développeur dans un environnement que beaucoup qualifieraient de “bunker numérique”.
Pas de GitHub Copilot, pas de ChatGPT, pas de services cloud.
Tout est filtré, loggé, surveillé. L’accès internet est soit inexistant, soit enfermé derrière un proxy dont je ne maîtrise ni les règles ni les exceptions.
Pourtant, comme beaucoup, j’ai goûté au confort des assistants IA : génération de tests, explications de code. Et revenir en arrière fait mal. On perd en autonomie.
Le problème est simple à formuler :
Comment retrouver l’efficacité apportée par les assistants IA modernes sans enfreindre les règles de sécurité, ni faire sortir de données sensibles ?
Cet article est le récit de cette recherche : comment, en tant que développeur dans un contexte restreint, j’ai reconstruit un environnement d’assistance IA 100 % local, en m’appuyant sur une architecture simple et quelques briques logicielles : modèles locaux, serveur d’IA, interface web, intégration IDE.
I. L’isolement technologique du développeur en environnement restreint
1.1. Les contraintes d’un environnement fermé
Dans certains contextes, les contraintes ne sont pas négociables :
- Secteur public sensible : ministères, défense, justice,...
- Entreprises critiques : banques, assurances,...
- Environnements sécurisés : salles blanches, réseaux fermés,..
Concrètement, ça donne :
- Blocage réseau strict : pas d’appel HTTP vers l’extérieur.
- Interdiction légale ou contractuelle de faire sortir des données (données de santé, données personnelles, secrets industriels).
- Comptes externes bloqués: impossible d’utiliser son compte GitHub, Google, Microsoft pour se connecter à des services tiers.
Ainsi, tous les outils cloud “modernes” nous deviennent d’un coup indisponibles.
1.2. Le besoin d’autonomie locale
Si je veux bénéficier d’assistants IA, je dois les héberger moi-même (sur mon poste ou sur un serveur interne), maîtriser entièrement où vont les données (idéalement : ne jamais les faire sortir du réseau). Enfin, je ne dois pas dépendre d’un service externe qui peut être coupé ou interdit du jour au lendemain.
L’objectif devient alors de recréer un Copilot / ChatGPT-like en local, dans un cadre maîtrisé, conforme aux contraintes de sécurité et de confidentialité.
Ainsi, les besoins sont assez clairs. Je veux un assistant conversationnel pour poser des questions, demander des explications, prototyper du texte ou du code. Ensuite, j'ai besoin d'une intégration directe dans l’IDE pour la complétion, le refactoring, la génération de tests. Tout cela en assurant de ne pas faire sortir les données : tout doit tourner sur la machine ou sur un serveur interne.
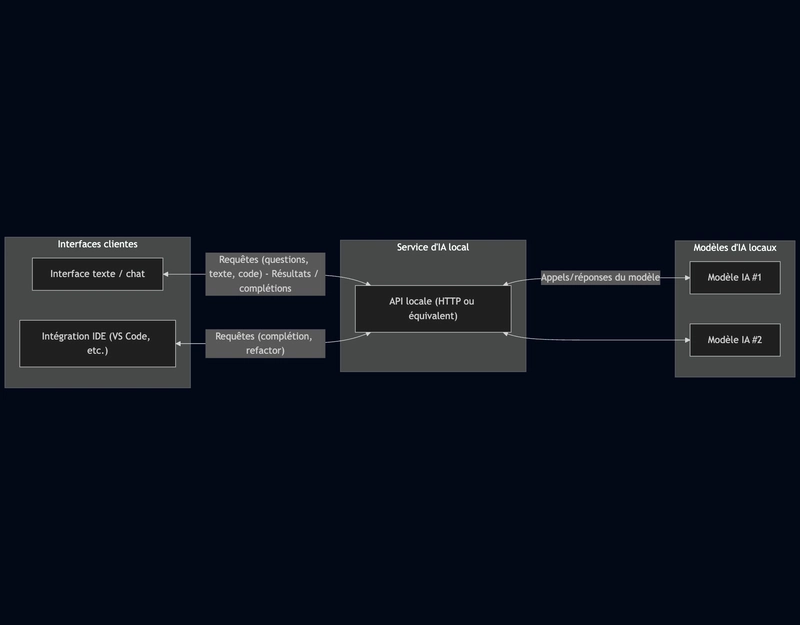
La réponse à ces besoins, c’est une architecture local-first :
- Un ou plusieurs modèles d’IA hébergés localement (sur le poste ou sur un serveur interne).
- Un service d’IA qui expose ces modèles via une API locale (HTTP ou équivalent).
- Une ou plusieurs interfaces clientes :
- une interface texte / chat pour discuter avec les modèles ;
- une intégration IDE pour assister l’écriture de code ;
- Aucune dépendance au cloud, aucune donnée qui sort de l’environnement sécurisé.
II. Mise en place pas à pas : construire son environnement IA privé
Je pars d’une situation réaliste : un poste de dev dans un environnement restreint, avec un accès à un dépôt interne mais pas d’accès direct à internet.
2.1. Choix du matériel
Il y a plusieurs configurations possibles. Première option, nous sommes en CPU-only, petite machine (8 à 32 Go de RAM). Nous pouvons seulement utiliser des modèles de taille réduite 7B à 70B de paramètres .
Seconde option, on met en place un serveur interne avec GPUs. On a ainsi accès à des modèles plus lourds, meilleure latence et une mutualisation pour plusieurs développeurs. Cela permet d’exposer un service IA centralisé au sein d’un réseau interne sécurisé.
2.2. Installation et configuration des outils
Service IA local
Première étape, nous devons installer le moteur de modèles locaux; un runtime capable de charger des modèles open-source et de les exposer via une API locale. Ollama s'impose en tant que figure de proue dans ce domaine notamment grâce aux nombreux modèles disponibles au téléchargement dans sa librairie.
brew install ollama | apt install ollama
Mon besoin est double. Je veux un modèle conversationnel et un modèle spécialisé sur le code.
ollama pull codellama:13b # Modèle code specific
ollama pull llama3.1:8b # Modèle conversationnelBien que téléchargé, ces modèles ne sont pas encore disponibles à la requête. Il faut lancer le serveur ollama puis lancer le modèle sur le serveur
ollama serve # Lance le serveur ollama
ollama run codellama:13b # Charge le modèle sur le serveur local ollama
(ollama run llama3.1:8b)Dorénavant, nous pouvons envoyer des requêtes aux modèles chargés

Remarque: Les modèles peuvent être téléchargés en amont sur un réseau autorisé, puis importés sur le réseau restreint via les procédures internes (clé USB sécurisée, transfert contrôlé, etc.).
Configuration de l'assistant code dans l'IDE
On veut configurer un assistant code dans notre IDE qui utilise le modèle spécialisé sur du code précédemment lancé via ollama. Dans mon cas, j’utilise VSCode et l’extension Continue
L'avantage est qu'elle embarque directement la connexion à ollama, cela rend sa configuration triviale.
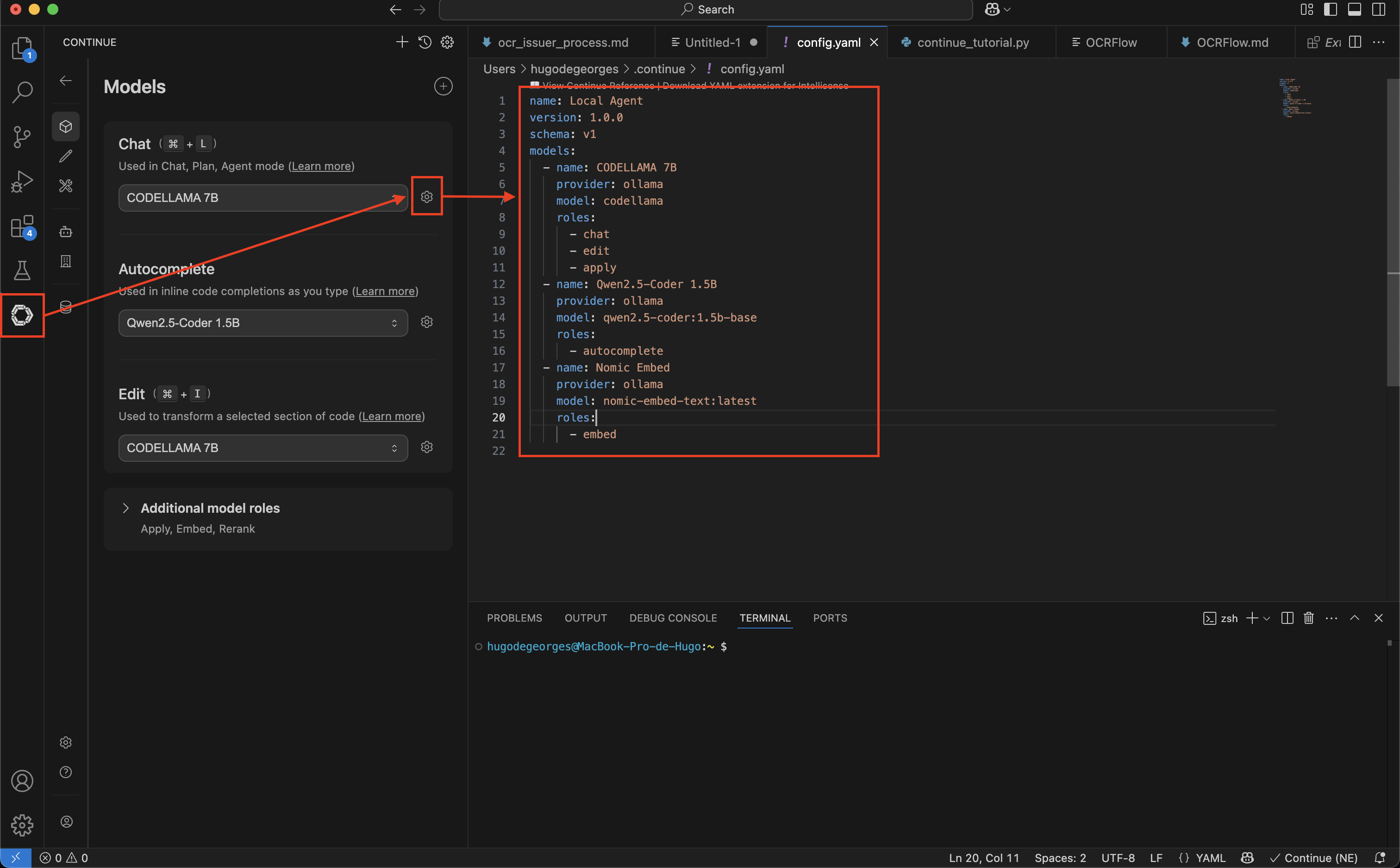
On peut lui définir plusieurs modèles en fonction de l'action réaliser dans l'IDE (autocomplétion, chat, ...). Pour cela on lui spécfie,
- le provider : ollama
- le modèle cible : codellama
- les roles associées
Les roles servent à assigner le modèle d'IA le plus efficace pour chaque type d'action dans VS Code :
chat: Il gère les conversations dans la barre latérale pour expliquer ou générer du code. Il nécessite un modèle "intelligent".autocomplete: Il suggère la fin des lignes en temps réel. Il nécessite un modèle très léger et rapide.edit: Il modifie ou refactorise directement un bout de code sélectionné (viaCmd+I).embed: Il indexe les fichiers pour permettre à l'IA de faire des recherches dans toute votre base de code.apply: Il gère la fusion propre du code généré par le chat directement dans les fichiers sources.
Interface texte/chat
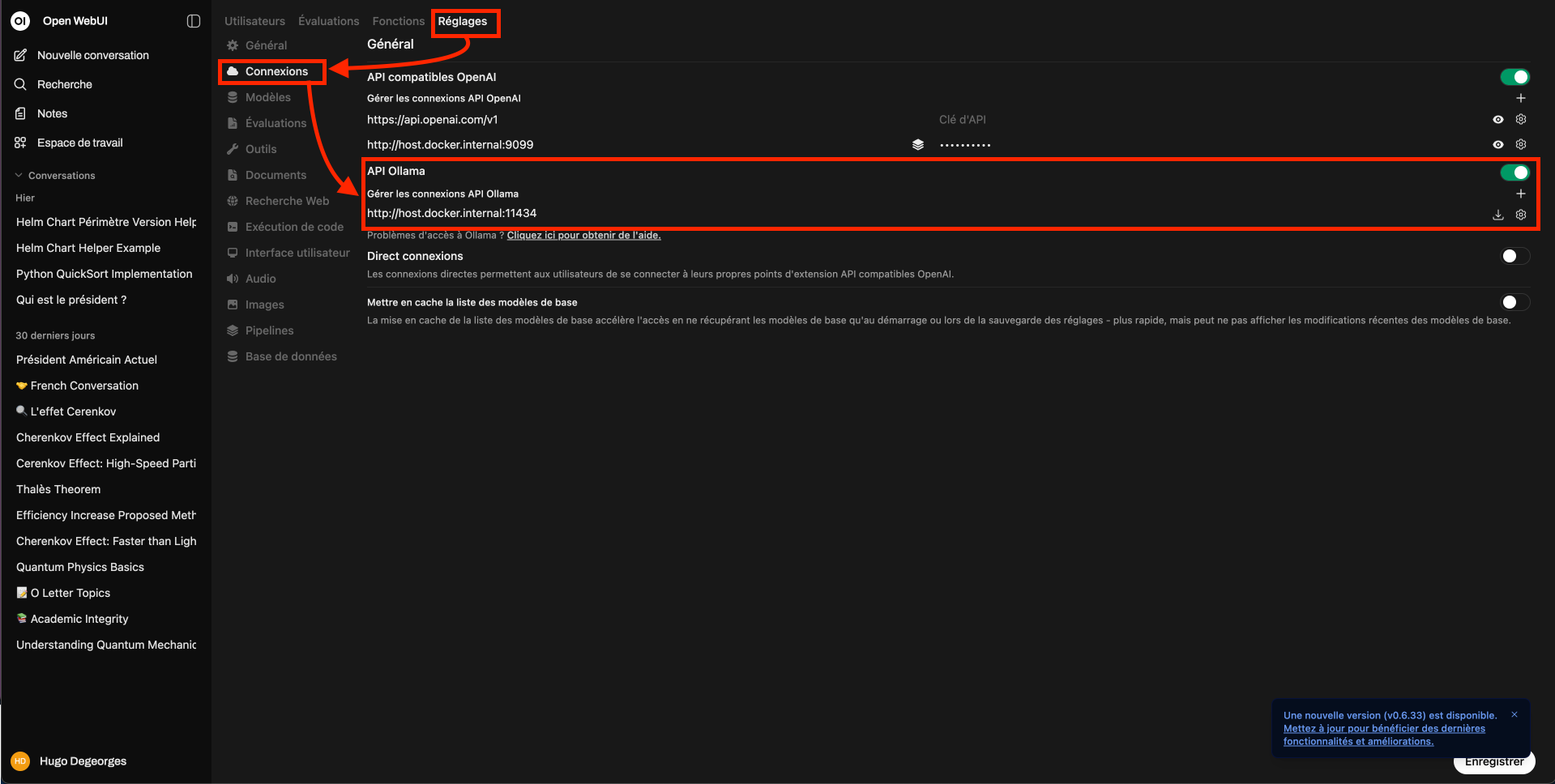
J’utilise la plateforme OpenWebUI qui propose une interface de conversation ergonomique et une intégration native avec Ollama. J’utilise la commande donnée dans le README OpenWebUI pour le lancement en configuration Ollama local.
docker run
-d # Detached: lance le conteneur en arrière plan
-p 3000:8080 # Mappe le port interne 8080 de docker sur le port 3000 de la machine
--add-host=host.docker.internal:host-gateway # Elle permet au conteneur
# (Open WebUI) de "voir" et de communiquer avec les services qui tournent sur
# la machine (l'hôte), en dehors de Docker
-v open-webui:/app/backend/data # créer un espace de stockage nommé open-webui géré par Docker
--name open-webui # Nom du conteneur
--restart always # Redémarrage automatique
ghcr.io/open-webui/open-webui:main # Image d'OpenWebUI utilisée
L’interface ollama est disponible sur http://localhost:3000.
Je configure OpenWebUI pour qu’il utilise le modèle llama3.1:8b comme modèle.
L’interface de chat est prête à l’utilisation.
III. Les utilisations concrètes : retrouver la “puissance” d’un assistant IA
Une fois l’infrastructure en place, la question devient : qu’est-ce que ça change vraiment dans mon quotidien de developpeur ?
Démonstration : Le "Sanitizer" de logs
Pour prouver l'efficacité de cette stack locale, prenons un scénario concret. Je dois développer un script d'anonymisation de logs en respectant une PSSI (Politique de Sécurité) interne stricte.
Voici les règles extraites du document PDF de spécification que je dois implémenter :
Règle 4.2 : Anonymisation des Emails. Tout email doit être haché (SHA-256) avec salage via la clé d'environnement 'APP_SECRET'. Règle 4.3 : Anonymisation des IP. Les adresses IPv4 doivent être tronquées (le dernier octet remplacé par 0).
Télécharger le PDF complet ici
Étape 1 : L'analyse documentaire
Dans un environnement classique, je devrais lire tout le document pour trouver ces règles. Ici, j'utilise OpenWebUI comme un analyste sécurité.
Ce qu'il se passe : Je charge le PDF de spécification directement dans OpenWebUI. Je demande ensuite à Llama 3.1 d'extraire uniquement les contraintes techniques liées aux IPs et Emails. Le modèle parcourt le document, isole les règles 4.2 et 4.3, et me fournit un résumé clair des implémentations attendues (salage, hachage, troncature).
Le gain : J'ai obtenu l'information critique sans avoir à tout lire et sans qu'aucune donnée confidentielle ne quitte mon réseau local.
Étape 2 : L'implémentation dans l'IDE
Une fois les contraintes identifiées, je bascule dans VS Code pour le développement pur, assisté par l'extension Continue.
Ce qu'il se passe :
Génération du squelette : Je demande au module de Chat de générer la classe LogSanitizer. Je lui fournis les règles précises récupérées à l'étape précédente. Il traduit littéralement la spécification en code Python (méthodes de hachage et de troncature).
Autocomplétion intelligente : C'est ici que le modèle spécialisé code (CodeLlama) prend le relais. Il suggère la fin des lignes, complète les imports et m'aide à écrire le bloc main et les tests unitaires pour vérifier que l'IP est bien tronquée.
Le résultat : En quelques secondes, j'obtiens un script fonctionnel, testé et conforme aux règles de sécurité, le tout sans quitter mon IDE.
Étape 3 : La documentation et la conformité
La boucle n'est pas bouclée tant que le code n'est pas documenté pour les auditeurs. Le modèle de Chat est bien meilleur rédacteur que le modèle de Code.
Ce qu'il se passe : Je retourne dans OpenWebUI et je lui fournis le code final généré. Je lui demande de rédiger un README.md à destination de l'auditeur de sécurité. L'IA analyse le script et génère une documentation qui prouve, point par point, que la Règle 4.2 (Emails) et la Règle 4.3 (IPs) sont bien respectées dans l'implémentation.
Le gain : On assure la traçabilité entre la spécification initiale et le code final, avec un effort de rédaction minimal.
IV. Bonnes pratiques : tirer le meilleur des modèles locaux
Le principal piège, c’est de vouloir “un gros modèle qui sait tout” et de se retrouver avec une machine qui rame et un service inutilisable.
4.1. Combiner plusieurs petits modèles plutôt qu’un seul géant
Dans un contexte restreint, la bonne stratégie, c’est la spécialisation :
- Un modèle orienté code
- Optimisé pour la complétion, le refactoring, la génération de tests.
- Un modèle orienté texte / documentation
- Entrainé pour la rédaction, la reformulation, les résumés.
Pourquoi opter pour cette stratégie ?
On réduit la charge : tous les usages n’ont pas besoin du plus gros modèle. On gagne en rapidité car un petit modèle spécialisé peut répondre bien plus vite qu’un modèle géant. On gagne également en optimisation mémoire : tous les modèles ne sont pas chargés tout le temps, on choisit en fonction du besoin. L’important est de choisir le modèle selon le contexte : pour le code, modèle A ; pour la doc, modèle B.
4.3. Sécurité et confidentialité
La grande force de cette approche locale, c’est la maîtrise. On n'a aucune donnée qui ne sort du réseau restreint. Les modèles et les outils peuvent être validés par les équipes sécurité avant mise en production interne. Mais ça ne nous dispense pas des bonnes pratiques. On vérifie que les logs ne contiennent pas de données sensibles en clair. On limite l’accès au service IA aux seules machines ou utilisateurs autorisés.
4.4. Les optimisations possibles
Une fois le socle en place, on peut aller plus loin notamment en nous spécialisant sur notre contexte via l'indexation locale des documentations internes (RAG) On indexe la documentation interne, le wiki, des specs, les procédures. L’assistant IA répond alors non seulement “en général”, mais aussi en se basant sur les documents de l’organisation.
V. Limites et perspectives
Rien n’est magique. Il faut être lucide sur ce que les modèles locaux apportent… et ce qu’ils n’apportent pas (encore).
5.1. Les contraintes actuelles
La contrainte locale implique nécessairement quelques limites.
D’abord, les machines locales sont “modestes”, la latence peut être élevée. Les gros modèles open-source restent gourmands. Ensuite, le contexte est limité. Il est difficile de charger simultanément de gros fichiers, beaucoup de docs ou de longs historiques. Il faut souvent faire des compromis sur la taille du contexte.
Enfin, la mise à jour des modèle est plus compliquée sans accès direct à internet, cela nécessite un processus spécifique (téléchargement sur un réseau ouvert, validation, transfert sur le réseau restreint).
5.2. Ce qui arrive : le futur de l’IA souveraine
Malgré ces limites, on reste optimiste. Les modèles open-source progressent vite, notamment sur le code. De plus en plus d’organisations publiques et privées investissent dans des infrastructures IA locales : clusters internes, frameworks pour déployer des assistants souverains, politiques de gouvernance dédiées. Les développeurs en environnement restreint n’auront plus cette impression d’être en retard d’une génération.
Conclusion : l’assistance IA dans un monde fermé
En partant d’un constat simple: je ne peux pas utiliser le cloud, mais j’ai besoin d’assistance IA, on peut construire une réponse claire :
- une architecture local-first,
- un service IA interne,
- plusieurs modèles spécialisés,
- des interfaces adaptées : IDE, web.
Ce n’est pas une copie parfaite de ce que proposent les géants du cloud, et ce n’est pas grave. C’est adapté au contexte, respectueux des contraintes de sécurité, et surtout : c’est sous notre contrôle.
En tant que développeur dans un “bunker numérique”, je ne suis plus spectateur de la révolution IA.


